Why LLMs are NOT blurry JPEGs of the Web
Chain of Thoughts(CoT), Emergence, In-context learning, and grokking concepts in ChatGPT

Let's start with some activation functions used in simple neural networks.
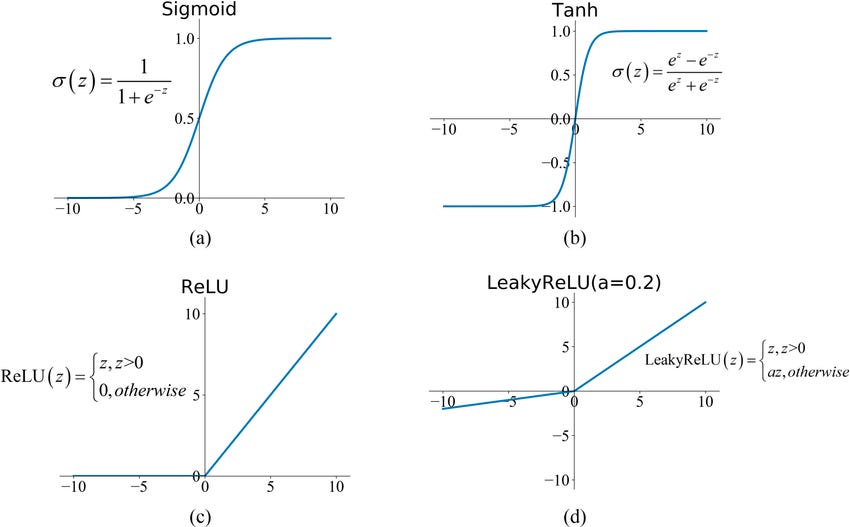
The implementations of those functions are also referred to as "nonlinear layers” in neural network architectures. They are important because they can help capture complex patterns and relationships by transforming the input data and preventing model overfitting. The nonlinearity breakthroughs are constantly happening in the development of new neural networks, and extending the law of influence into the realm of large language models (LLMs).
Many people's understanding of LLMs (or, more generally, big neural networks) is still from several years ago. The two most common opinions are that "neural network has to be trained for a specific task from a specified dataset" or "LLMs are simply doing statistical probabilities to predict the next word." However, the recent behaviors of chatGPT (GPT 3.5) show that it is actually performing reasoning or inferring given prompts or contexts.
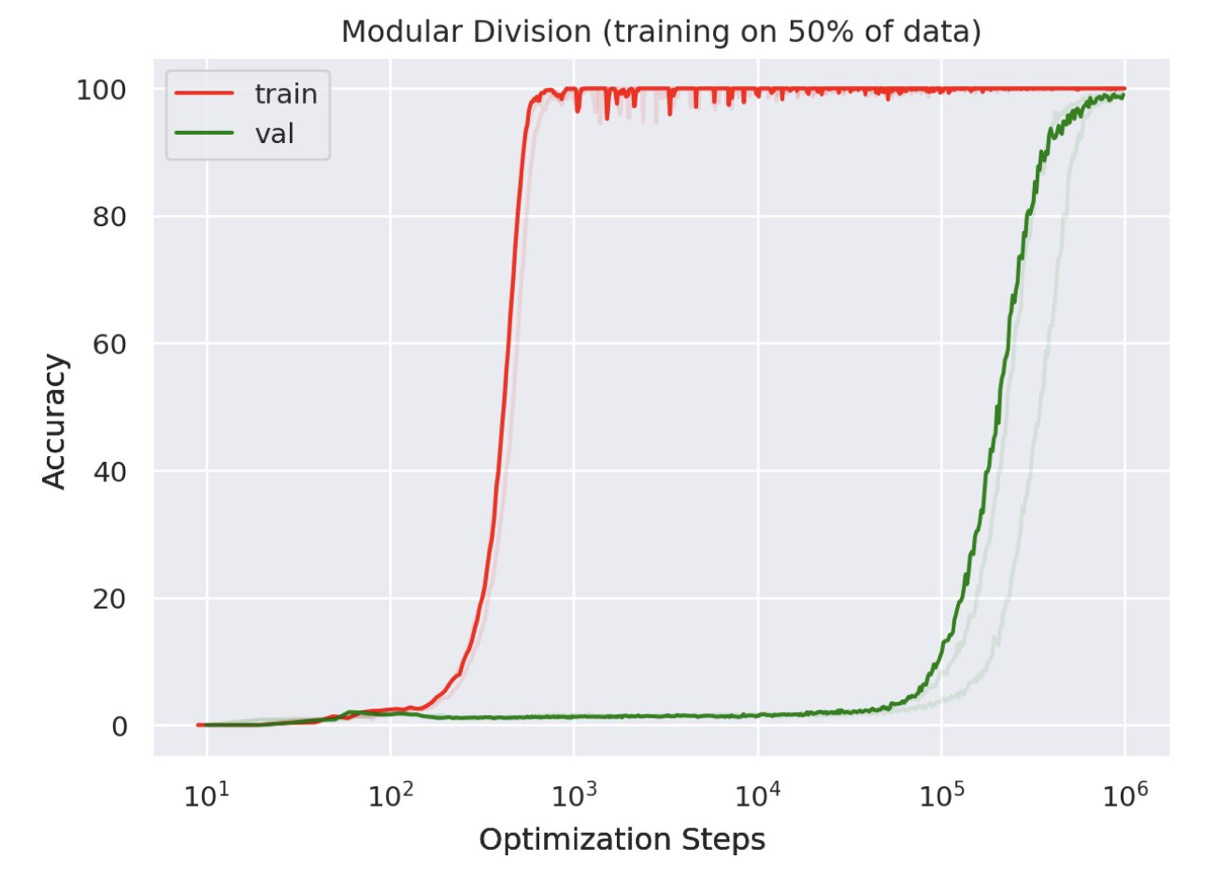
Grokking
Grokking, which might be paraphrased as "epiphany", describes the phenomenon where a neural network can suddenly generalize when it continues optimizing after achieving perfect training accuracy. You can think of it as a model going through an "aha moment." It was observed for the first time in 2022 by OpenAI. Intuitively, Grokking is a nonlinear occurrence that has no concrete explanation yet. The answer may lie among (or in the combination of) the three cutting edge research areas in AI: Chain-of-Thought(CoT), Emergent Abilities, and In-Context Learning.
If you have read any of Tim Urban's articles(or his new book), you probably know that traditional neural networks, no matter how many parameters they have, could be approximated to the primitive mind. Following the "data fitting" mechanism, the network gives an output of an answer directly, with no logic or reasoning process. For example, if you train your model with only the cats and dogs dataset, there is no way that a neural network can identify a Pikachu based on inference. This limitation is an obvious gap for neural networks on the way to general intelligence: what sets intelligence apart from intuition is that intelligence can ‘think slowly’ in addition to instinct, i.e., step-by-step reasoning type of thinking.
Chain of thought
Enters Chain of thought(COT). COT is an engineering attempt to reproduce the higher mind model: you may not be able to teach a neural network to reason directly, but you can hardwire it to output a step-by-step reasoning format. An analogy here would be your professor telling you that "procedures worth the majority of the credits". Forcing a neural network to write out a thought process may not be the same as actually thinking logically, but it doesn't matter, since it outputs a literal version of the entire chain of thought, and the result is essentially the same.
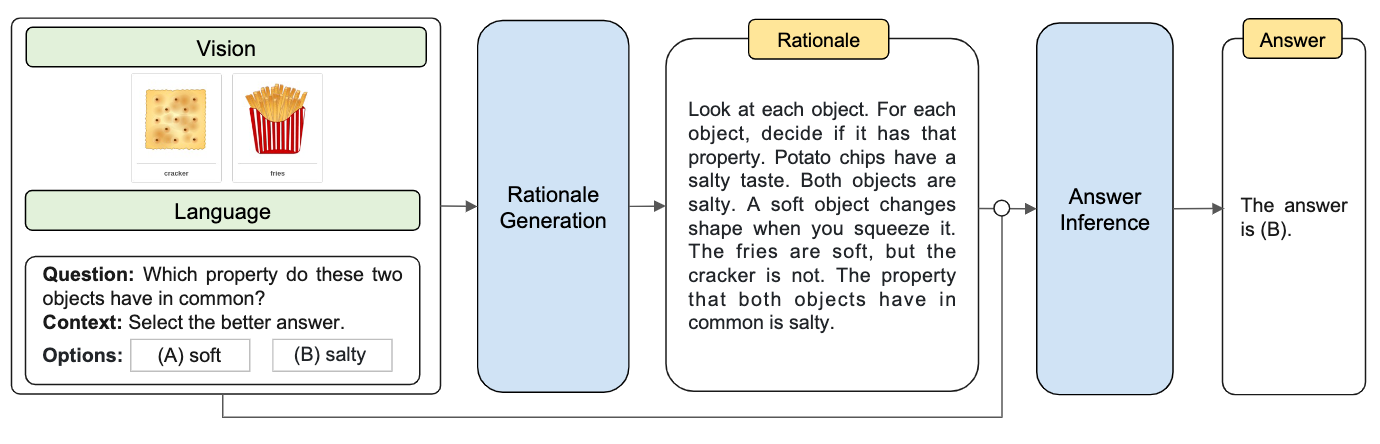
From the Stanford and Google paper 'Emergent Abilities of Large Language Models', you can see the nonlinearity and the ‘threshold’ nature of COT. As shown in (A) below, COT prompting can significantly improves reasoning abilities of large language models, allowing them to solve multi-step problems that require abstract reasoning, such as math word problems. As shown in (B), chain-of-thought prompting performs worse than directly returning the final answer until a critical size (10^22 FLOPs), at which point it does substantially better.

Amazon’s 'Multimodal Chain-of-Thought Reasoning in Language Models' took it further and created a Multimodal-CoT that incorporates language (text) and vision (images) modalities. The model is not trained to choose B based on keywords(cracker, fries). Instead, it has the rationale generated given language and vision inputs, put the rationales and the original inputs together, then infer the answer. For every specific step, the model is still using the primitive mind. But as the whole procedure, it simulates the process of higher-mind thinking.
Emergent abilities
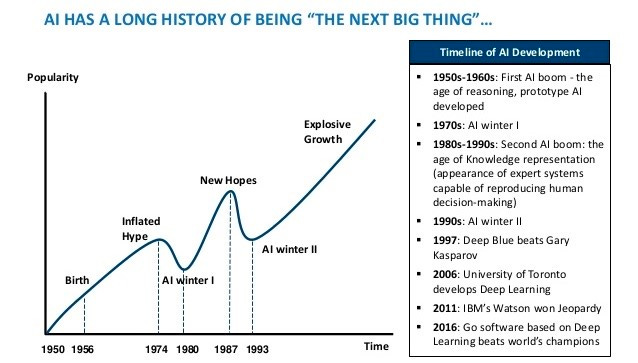
Looking back at the Stanford paper, emergent abilities in LLMs are defined as "an ability is emergent if it is not present in smaller models but is present in larger models'. As soon as the complexity of a neural network and the variety of training samples exceed a certain size, abstract inference structures suddenly emerge spontaneously in the neural network. The 'quantitative change leads to qualitative change' nonlinearity is once again shown in the evidence.

On the other hand, because emergence is nonlinear, it is extremely difficult to predict its development. This nonlinearity is also at the root of the wave-like development of AI: you can feel like nothing is getting done for years(remember AlphaGo?), then suddenly have a dramatic burst of growth, and then probably move on to the next winter.
In-context learning
But the point is that GPT3.5 and some other LLMs have definitively moved past significant thresholds in many ways that are out of expectations. This has led to a rapid reassessment of the entire perception of model capabilities. The most typical is in-context learning, which is a mysterious emergent behavior in LLMs. In context learning is a way to use language models to learn tasks given only a few examples. In-context learning allows users to quickly have models for new use cases, such as code generation and writing samples, without worrying about fine-tuning.

Following the paper "An explanation of In-context learning as implicit Bayesian Inference', in-context learning ability could be explained as prompts that "wake up' the latent ability inside the per-trained model, and the combined distribution can let the model perform 'primitive' type of thinking. Although the framework is just a proposed speculation, it could possibly mean that with more latent abilities (a bigger model) and better quality prompts (through preprocessing), LLMs can unlock new potentials in a nonlinear way.
Conclusion: LLMs are NOT a blurry JPEG of the web
Based on the @farmostwood explanation, the external representations of LLMs can be decomposed into three levels: "knowledge base" + "reasoning and inference ability" + "expressiveness". Most discussions about ChatGPT have focused on the first and the third, ignoring the revolutionary progress of the second piece. In fact, similar to the trend of 'separation of storage and compute', you can imagine the future of AI could be split into modules, with the knowledge base being handled separately (Llama-index and LangChain are great open-source tools for module assembly). With the inference core, preprocessing and post-processing models, LLMs are not blurry representations of the internet, but early teasers of what AGI could be capable of in the future.